All Tests Crashed, CI Passed: The One-Line Vitest Bug Behind It.
The Symptom
Our backend service has hundreds of integration tests. Each test file spins up an application instance in a beforeAll hook, runs assertions against it, and tears it down in afterAll. The application constructor validates that required environment variables are present — if any are missing, it calls process.abort() to fail fast.
One day, a required environment variable was removed from the CI pipeline configuration. Every single test file began crashing. Not failing — crashing. The process.abort() call in the application constructor fires before any test case runs, killing the Node.js worker process with a native signal. There’s no stack trace, no caught exception, no graceful teardown. The process is simply gone.
However, the CI pipeline remained green. Azure DevOps reported the test step as passed: zero failures, zero warnings, and a clean build.
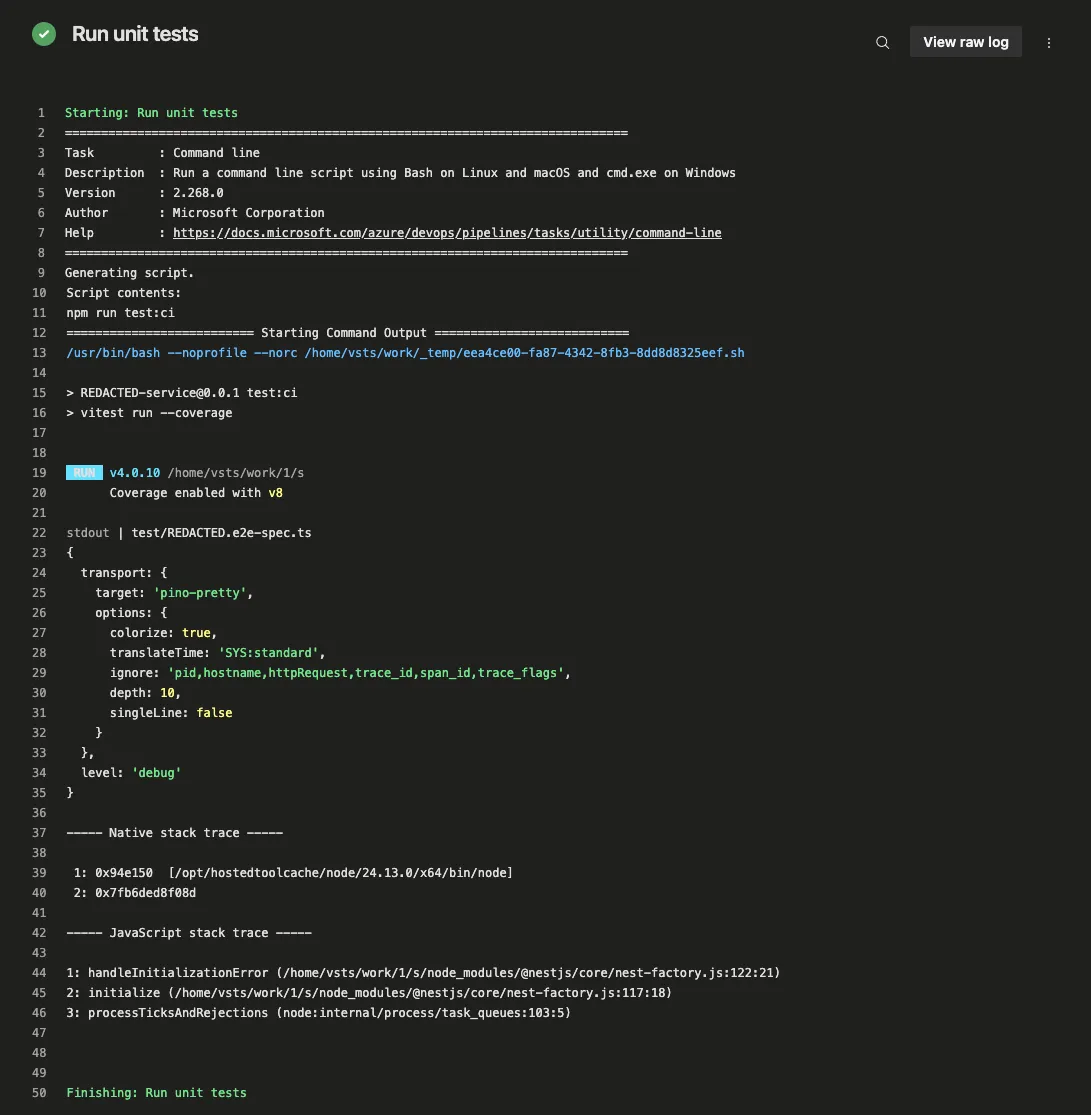
Azure DevOps marks the step as passed even though the logs show a native crash stack trace from test workers.
The Investigation
Initial suspicion focused on Azure DevOps: exit-code handling, shell escaping, or YAML configuration. A quick local test confirmed the problem:
npm test
echo $? # 0Vitest itself was exiting with code 0. Every test file crashed via process.abort() — a native process termination that cannot be caught by try/catch — and Vitest still reported success.
Isolating the Trigger
The crash originates in the application constructor, which is called during a beforeAll hook. Simplified, the pattern looks like this:
class AppService {
private readonly apiUrl: string;
constructor(config: ConfigService) {
// Throws if API_URL is not set in the environment.
// In our app setup, bootstrap error handling catches this and calls process.abort().
this.apiUrl = config.getOrThrow<string>('API_URL');
}
}The test file boots the application in beforeAll:
describe('App (e2e)', () => {
let app: Application;
beforeAll(async () => {
// Application constructor validates config.
// If API_URL is missing, process.abort() is called.
app = await createApplication(AppModule);
await app.init();
});
it('should respond', () => {
expect(app.get(AppService)).toBeDefined();
});
});The key detail is that createApplication is async. The constructor validation happens inside an awaited promise chain. When the config check fails, the framework’s error handler calls process.abort(), but this occurs after the Vitest worker process has already completed its startup handshake with the main process.
The bug has nothing to do with the application framework, though. It reproduces with nothing but Vitest and a bare process.abort():
import { describe, expect, it, beforeAll } from 'vitest';
describe('Crash', () => {
beforeAll(async () => {
await new Promise((resolve) => setTimeout(resolve, 10));
process.abort();
});
it('should never reach this', () => {
expect(true).toBe(true);
});
});The await before process.abort() is critical. It ensures the crash happens after the worker has fully started. A synchronous process.abort() — at the module top level or in a non-async beforeAll — is surfaced correctly by Vitest in this setup. The false-positive path discussed in this post requires crashes that happen after the worker has completed its startup handshake with the main process. An async beforeAll — the kind you’d write to boot an application that validates its config in a constructor — crosses that boundary.
Finding the Threshold
The bug does not appear with a single crashing test file. With one crash and one passing test, Vitest detects the error, prints it, and exits 1. At higher counts of crashing files, Vitest silently exits 0 with no summary — only raw native stack traces on stderr.
In this repository’s default file layout, the boundary was maxWorkers + 1.
Vitest’s fork pool defaults to maxWorkers = os.availableParallelism() - 1 (defined in resolveMaxWorkers in pool.ts). On an Apple M-series machine with 14 available cores, that’s 13 workers. With 13 crashing files plus one passing file (14 total), the passing file runs — a slot is free. With 14 crashing files plus one passing file (15 total), the passing file never gets scheduled.
This was verified systematically in this repo by overriding --maxWorkers:
maxWorkers | Crash files at boundary | Exit code | Crash files above | Exit code |
|---|---|---|---|---|
| 2 | 2 | 1 | 3 | 0 |
| 4 | 4 | 1 | 5 | 0 |
| 6 | 6 | 1 | 7 | 0 |
| 8 | 8 | 1 | 9 | 0 |
| 10 | 10 | 1 | 11 | 0 |
In this repro layout (test/pass.spec.ts plus generated test/crash-*.spec.ts), the pattern was deterministic. Scheduling details can shift when files are renamed or reordered, but the underlying failure mode is the same: once crashed workers saturate the pool and cleanup is skipped, queued files may never run and Vitest can exit 0.
The Root Cause
The bug is a single line in Vitest’s Pool.schedule() method (packages/vitest/src/node/pools/pool.ts). Here is the relevant section from Vitest 4.0.16:
// pool.ts — schedule() method (vitest <= 4.0.16)
runner.on('message', onFinished);
if (!runner.isStarted) {
runner.on('error', (error) => {
resolver.reject(
new Error(`[vitest-pool]: Worker ${task.worker} emitted error.`, { cause: error }),
);
});
const id = setTimeout(
() => resolver.reject(new Error(`[vitest-pool]: Timeout starting ${task.worker} runner.`)),
WORKER_START_TIMEOUT,
);
await runner.start({ workerId: task.context.workerId }).finally(() => clearTimeout(id));
}
const span = runner.startTracesSpan(`vitest.worker.${method}`);
runner.request(method, task.context);
await resolver.promise.catch((error) => {
span.recordException(error);
throw error; // ← THE BUG
}).finally(() => {
span.end();
});
// --- cleanup code below this point ---
const index = this.activeTasks.indexOf(activeTask);
if (index !== -1) this.activeTasks.splice(index, 1);
// ... runner.stop(), freeWorkerId(), etc.The Worker Lifecycle
To understand why this matters, you need to understand Vitest’s fork-pool worker lifecycle:
-
runner.start()— Forks a child process, sends a{ type: 'start' }message with configuration, and waits for the worker to reply with{ type: 'started' }. This is the handshake. It completes before any test code runs. -
runner.request('run', context)— Sends a{ type: 'run' }message. The worker imports the test file, runsbeforeAllhooks, executes tests, and sends back{ type: 'testfileFinished' }. -
resolver.promise— Resolves when theonFinishedhandler receivestestfileFinished, or rejects when the error handler fires.
When process.abort() is called inside an async beforeAll — such as when an application constructor validates its environment and finds a missing variable — the worker has already completed step 1 (the startup handshake). It crashes during step 2, partway through running the beforeAll hook. The child process dies, the Node.js exit event fires, and PoolRunner.emitUnexpectedExit creates an error and emits it on the runner’s event emitter.
Why the Error Handler Works (Sometimes)
The runner.on('error', ...) listener is attached inside the if (!runner.isStarted) block. This listener calls resolver.reject() when a worker error occurs. Since each test file gets its own fresh runner (with the default isolate: true), the error listener is always present for the first — and only — task on that runner.
When the worker crashes, the error listener fires, resolver.reject() is called, and resolver.promise rejects. Up to this point, the failure path behaves as intended.
Where It Goes Wrong
The .catch() handler on resolver.promise records the error for OpenTelemetry tracing, then re-throws it:
await resolver.promise.catch((error) => {
span.recordException(error);
throw error; // re-throw skips all cleanup
});This re-throw causes schedule() to jump to its outer catch block:
catch (error) {
return resolver.reject(error); // no-op: already rejected
}The outer catch tries to reject the resolver, but it is already rejected — this is a no-op. Then schedule() returns. Everything after the await resolver.promise line is skipped:
this.activeTasks.splice(index, 1)— the task stays in the active listrunner.stop()— the dead worker is never cleaned upthis.freeWorkerId(poolId)— the pool slot is never released
The worker slot is permanently occupied by a dead process. With enough dead workers, the pool is saturated:
// Pool.schedule() — first line
if (this.queue.length === 0 || this.activeTasks.length >= this.maxWorkers) {
return; // nothing to do... or so it thinks
}Any queued test files — including passing ones — will never be scheduled.
The Silent Exit
When the pool finally shuts down, Vitest aggregates results:
modules = specifications.map(s => s.testModule).filter(s => s != null)Crashed workers never sent testfileFinished, so their spec.testModule is undefined. After filtering, modules is empty. As a result:
if (hasFailed(this.state.getFiles())) process.exitCode = 1;hasFailed([]) returns false. The exit code stays at 0. No test summary is printed because there are no results to summarize.
Reproducing the Bug
A minimal reproduction is available in MikeRossXYZ/vitest-fork-pool-silent-failure. It requires only Vitest (the repo currently pins 4.0.16, and the bug reproduces on 4.0.10 through 4.0.16) — no application framework, no config library, and no other dependencies.
The generate-tests.ts script dynamically creates exactly os.availableParallelism() test files from test/crash-template.ts. Each generated file calls process.abort() inside an async beforeAll — simulating what happens when an application constructor validates its environment and calls process.abort() on failure. The await before the abort ensures the worker has completed its startup handshake, matching the real-world timing of a constructor that runs inside an async initialization chain.
One additional file (test/pass.spec.ts) contains a passing test but is never scheduled because the pool is saturated.
git clone https://github.com/MikeRossXYZ/vitest-fork-pool-silent-failure.git
cd vitest-fork-pool-silent-failure
npm install
npm test
echo $? # 0 — all tests crashed, Vitest says "success"To verify the threshold behavior on a single machine, override --maxWorkers:
# Create exactly 5 crash files from the template, then run with maxWorkers=4
rm -f test/crash-*.spec.ts
for i in 0 1 2 3 4; do
sed "s/{{INDEX}}/$i/g" test/crash-template.ts > test/crash-$i.spec.ts
done
# With maxWorkers=4 in this layout:
# 4 crash files + pass.spec.ts → exit 1 (pass test can still run)
# 5 crash files + pass.spec.ts → exit 0 (all slots consumed by crashed workers)
npx vitest run --maxWorkers=4Attempting to Contribute the Fix
When I traced this bug to a single throw error in Vitest’s fork pool, I believed I had found a novel issue. The root cause was clear, the reproduction was deterministic, and the fix was straightforward: remove the re-throw so cleanup always runs.
I then prepared to file an issue with the library. I had long wanted to contribute a meaningful fix to a widely used open-source project. My local environment was on v4.0.16, so I upgraded to v4.0.18 first… and the failure was gone 🫠
What the Vitest Team Knew
After reviewing the library’s GitHub for what changed, I did not find an explicit changelog note for this behavior. However, the relevant threads were as follows:
Issue #9271, filed by Vitest maintainer @sheremet-va, described a different problem: Vitest hangs when poolRunner.start() throws an error. The scenario was a startup failure — the worker’s env.js throws before the handshake completes — not a mid-test crash. The symptoms were different (hang vs. silent exit 0), the trigger was different (start-time throw vs. post-start process.abort()), and the reproduction was different.
@AriPerkkio picked up the issue and authored PR #9337. The PR’s test creates a mock worker whose start() method rejects, so it covers start-time failures only. In a review comment, AriPerkkio noted: “We should not throw anything in this scope. resolver.reject is intentionally used for that instead.” That observation — recording the error without re-throwing — is the same fix required for this failure mode. However, it was introduced while solving a startup hang, not a mid-test exit-code issue.
No issue was filed for the specific bug described in this post. No report explicitly described a beforeAll process.abort() path causing Vitest to exit 0. The PR’s test suite does not cover that scenario. The fix was introduced because the re-throw was generally incorrect; it broke cleanup for any worker failure, whether at startup or mid-test.
What I Learned Anyway
I did not submit the issue or fix PR, but the investigation was still valuable. It clarified Vitest’s fork-pool architecture: worker lifecycle, handshake protocol, scheduling gate, and the promise chain that connects them. It also clarified why process.abort() behaves differently from process.exit() in a forked worker, and why crash timing relative to the startup handshake changes the outcome.
I also now have a reproduction repository and this write-up documenting a failure mode not explicitly covered by the current tests. If a variant resurfaces, this analysis should shorten diagnosis.
The next one might still have my name on it 🚀
What Changed in Vitest 4.0.17
PR #9337 — “fix(pool): handle worker start failures gracefully” — was authored by @AriPerkkio, merged on December 29, 2025, and shipped in Vitest 4.0.17 on January 12, 2026. It resolved issue #9271, which was filed by @sheremet-va (a Vitest maintainer) about Vitest hanging when poolRunner.start throws.
The PR made three changes to Pool.schedule():
1. Catch start failures explicitly
// Before (4.0.16)
await runner.start({ workerId: task.context.workerId }).finally(() => clearTimeout(id));
// After (4.0.17)
await runner.start({ workerId: task.context.workerId })
.catch(error =>
resolver.reject(
new Error(`[vitest-pool]: Failed to start ${task.worker} worker...`, { cause: error }),
),
)
.finally(() => clearTimeout(id));2. Guard against sending requests to dead workers
// Before (4.0.16)
const span = runner.startTracesSpan(`vitest.worker.${method}`);
runner.request(method, task.context);
// After (4.0.17)
let span: Span | undefined;
if (!resolver.isRejected) {
span = runner.startTracesSpan(`vitest.worker.${method}`);
runner.request(method, task.context);
}This was enabled by wrapping the resolver’s reject function to track an isRejected flag:
function withResolvers() {
// ...
const resolver = {
promise,
resolve,
reject: (reason: unknown) => {
resolver.isRejected = true;
reject(reason);
},
isRejected: false,
};
return resolver;
}3. Stop re-throwing errors (the critical fix)
// Before (4.0.16) — re-throw skips cleanup
await resolver.promise.catch((error) => {
span.recordException(error);
throw error;
}).finally(() => {
span.end();
});
// After (4.0.17) — error is recorded but not re-thrown
await resolver.promise
.catch(error => span?.recordException(error))
.finally(() => span?.end());This is the change that fixes the mid-test crash case. Without the re-throw, execution continues to the cleanup code: the active task is removed, the worker is force-stopped, and the pool slot is freed.
The force-stop was also added in the same PR:
// Before
runner.stop()
// After
runner.stop({ force: resolver.isRejected })This ensures crashed workers are terminated immediately rather than waiting for a graceful shutdown response that will never come.
Why It Was Described as a “Start Failure” Fix
The PR title — “handle worker start failures gracefully” — and the linked issue describe a scenario where poolRunner.start() itself throws. That is a different code path from this scenario, where process.abort() fires inside a beforeAll hook after the worker has already started. The fix to the .catch() handler on resolver.promise (change #3) is generic: it prevents any worker error from skipping cleanup, whether the error occurs during startup or test execution.
This is a case where a targeted fix for one failure mode incidentally resolved a broader class of bugs. The re-throw had been there since the pool was first written, and it affected every scenario where a worker died after starting.
We verified this by patching a single line in Vitest 4.0.16’s bundled source — removing the throw error from the .catch() handler and changing nothing else. The exit code changed from 0 to 1. That one line was the entire root cause.
Lessons
The location and timing of the crash matter. A synchronous process.abort() at module scope is surfaced by Vitest in affected versions. An async beforeAll crash can also be surfaced when only a small number of files crash. The silent exit-0 behavior appears when enough post-handshake crashes accumulate to saturate the pool while cleanup is being skipped.
Native process crashes are different from exceptions. process.abort() does not follow JavaScript’s error propagation model. Any test runner that forks worker processes must handle cases where a worker simply vanishes; this is not equivalent to a thrown exception.
CI pipelines trust exit codes implicitly. Azure DevOps, GitHub Actions, and every other CI system treat exit code 0 as success. A test runner that exits 0 when all tests crashed is indistinguishable from a test runner that exits 0 when all tests passed. There is no second layer of verification.
Re-throwing caught errors is dangerous in async cleanup flows. The root cause was a throw error inside a .catch() handler that preceded essential cleanup code. In synchronous code, try/finally ensures cleanup runs regardless of failure. In promise chains, a re-throw in .catch() skips everything after the await, including cleanup that is not wrapped in .finally(). The fix was to stop re-throwing.
Threshold bugs are hard to find. In this repro layout, with one crashing test, Vitest exits 1. With twelve, Vitest exits 1. With thirteen, Vitest exits 1. With fourteen — on this specific machine and file layout — Vitest exits 0. The bug is invisible in small test suites and tends to manifest only when enough workers crash to saturate the pool.
References
- MikeRossXYZ/vitest-fork-pool-silent-failure — Standalone reproduction repository for this issue
- Vitest PR #9337 — fix(pool): handle worker start failures gracefully (the fix)
- Vitest issue #9271 — Vitest hangs if
poolRunner.startthrows an error (the linked issue) - Vitest PR #9272 — fix(reporter): report test module if it failed to run (related reporter fix, same release)
- Vitest v4.0.17 release — Released January 12, 2026